To better understand what is a Large Language Model (LLM), we’re going to break down the term ‘LLM’ word by word, explore its core components, and delve into the underlying concepts to deepen our understanding. At the end of this article, we’ll bring everything together into a concise summary.
Model
Peeling back the layers of an LLM, it’s essentially a machine learning model at its heart. The model acts as the core computational engine—taking in input, crunching through it, and spitting out the output.
Through its actions – essentially “taking in”, “crunching through” and “spitting out” – we can break down the key components of a Machine Learning Model into:
- Input Data: The dataset used to train the model
- Algorithm: The method or technique used to train the model (e.g., neural networks).
- Parameters: The internal variables of the model that are learned during training to map inputs to outputs.
- Output: The predictions or decisions made by the model based on new input data.
It’s like you’re teaching a dog a new trick. You show it examples (data) of what you want it to do, and you reward it when it gets it right. Over time, the dog learns to associate the action with the reward and performs the trick reliably. A machine learning model learns in a similar way.
So how much data are we using for the training purpose? A lot!
Large
The “Large” in LLMs refers to the massive size of the datasets they are trained on and the complexity of their neural network architectures.
Essentially, LLMs are trained on enormous amounts of text data, often containing billions of words. For instance, it’s known that GPT-3 was trained on approximately 570 GB of filtered text data, derived from a 45 TB dataset of unfiltered text. For GPT-4, while OpenAI has not released specific details about the dataset size, it is likely that the training data was scaled up further, potentially in the range of hundreds of terabytes or more.
Additionally, these models have millions or even billions of parameters within their deep learning architectures, enabling them to capture intricate patterns in language. For instance, GPT-3 contains 175 billion parameters. GTP-4’s exact number of parameters hasn’t been publicly disclosed but some reports suggest it could have up to 1.8 trillion parameters.
So, the “large” signifies the scale of both the data and the model. We feed a lot to the model, and the model itself has to be big enough digest all these data.
Language
Now let’s look at the “Language” part. LLMs are called “language models” because their primary function is to understand and generate human language.
Understanding Language:
- Vast Vocabulary: LLMs are trained on massive datasets of text and code, giving them exposure to an enormous vocabulary and a wide range of language styles.
- Grammar and Syntax: They learn the rules of grammar and sentence structure, allowing them to parse and understand the relationships between words in a sentence.
- Semantics and Context: LLMs go beyond just recognizing words; they also learn the meanings of words and how those meanings can change depending on the context in which they are used.
- Nuances of Language: They can grasp subtleties like sarcasm, humor and different writing styles.
Generating Language:
- Coherent Text: LLMs can produce text that is grammatically correct, flows logically, and is relevant to the context.
- Variety of Formats: They can generate different kinds of text, such as poems, articles, code, and even dialogue.
- Adapting to Style: LLMs can be prompted to generate text in a specific style or tone, mimicking the writing of a particular author or the conventions of a certain genre.
Going back to the “teaching a dog a new trick” analogy we used earlier. There are different “tricks” we can teach a model to do. In the LLM case, we are teaching it to be able to process, understand and generate natural language.
Natural Language Processing (NLP)
Talking about processing and generating natural language, we’ll can’t bypass another term – Natural Language Processing (NLP). What’s the difference between NLP and LLM?
In short, LLM is a subset of NLP.
NLP is a broad field of AI focuses on enabling computers to understand, interpret and generate human language. As a subset of NLP, LLM is a specific deep learning model designed to understand and generate human language model.
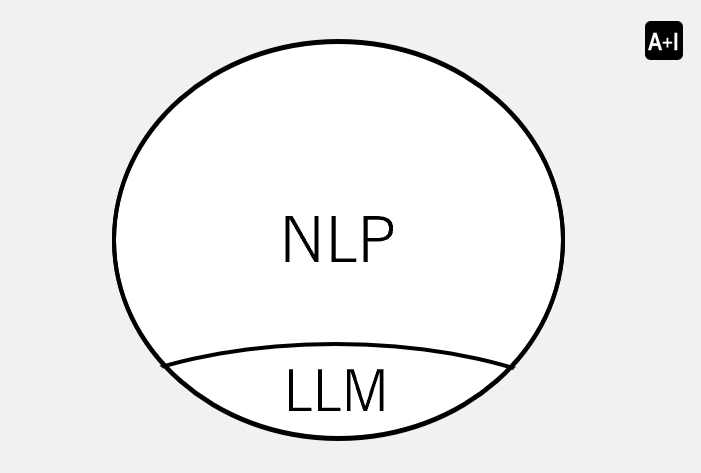
Another subset of NLP but not necessarily an LLM is Rule-Based systems. Rule-Based systems rely on predefined rules and patterns. A typical example is if-then rules.
Now, let’s take a specific use case in NLP, such as a Grammar Checker, to explore the differences between a Rule-Based Grammar Checker and an LLM-Based Grammar Checker.
- Rule-Based Grammar Checker: A rule-based grammar checker relies on predefined grammar rules and patterns created by linguists and language experts. It has limited flexibility and can fail on complex sentence structures.
- LLM-Based Grammar Checker: An LLM-based grammar checker uses deep learning to learn from millions of text examples to understand context, meaning and intent. This enables it to predict and suggest corrections based on real-world language usage.
In a shortened way to describe the key difference between these two, a Rule-Based Grammar Checker is predefined, where an LLM-Based Grammar Checker is trained.
Deep Learning (DL)
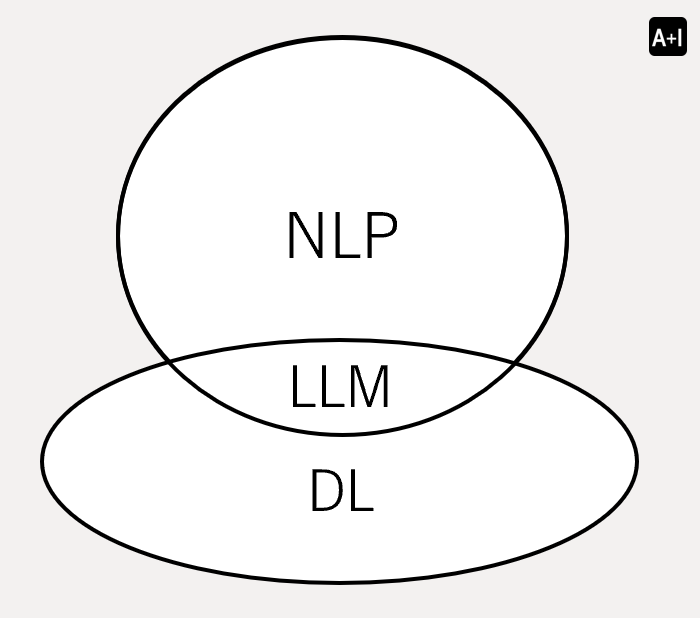
Having explained the relationship between LLM and NLP, let’s extend the drawing towards another angle. We’ve mentioned Deep Learning (DL) several times earlier. What’s the relationship between LLM and DL?
As shown in the diagram, LLM can be viewed from another perspective as a subset of DL.
DL is a subset of Machine Learning (ML) that focuses on training artificial neural networks with multiple layers (hence the term “deep”) to learn and make decisions from data. These neural networks are inspired by the structure and function of the human brain, consisting of interconnected nodes (or neurons) organized in layers.
Using OpenAI’s products as examples, ChatGPT is an instance of an LLM, whereas Sora and DALL-E are not. While ChatGPT specializes in text generation, Sora and DALL-E focus on generating images and videos. However, all three are built on Deep Learning frameworks.
Machine Learning (ML)
Earlier, we introduced Deep Learning (DL) as a subset of Machine Learning (ML). Now, as we wrap up this article, let’s take a closer look at ML
ML is a broader field that encompasses various techniques that enable computers to learn from data and improve their performance on specific tasks without being explicitly programmed.
Instead of relying on rigid rules, ML systems use algorithms to identify patterns and relationships within large datasets. These algorithms are trained on historical data, allowing them to make predictions, classify information, or uncover hidden insights.
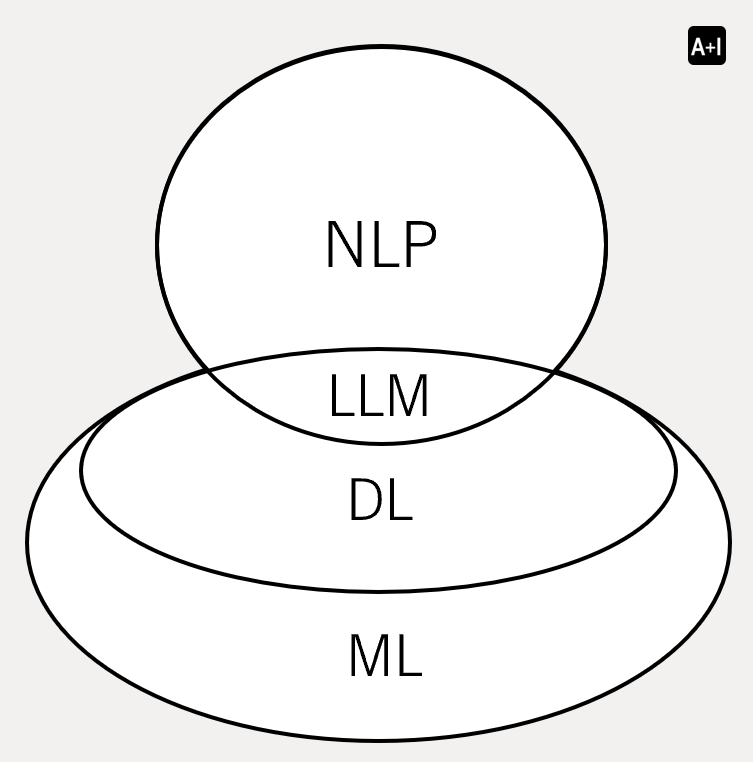
If we consider DL as a modern approach in ML, we can group the rest of ML as Traditional Machine Learning. This category includes algorithms and techniques that do not rely on deep neural networks and are often simpler, more interpretable, and require less computational power compared to DL. These methods are particularly effective for structured data and smaller datasets. One example is Tree-Based Models, e.g. Decision Trees.
Summary
With all the above explained, now if we zoom back to LLM we can summarize it as:
“An LLM is a large-scale artificial intelligence system built using deep learning (DL) techniques and trained on massive amounts of text data to understand and generate human language. It is a type of model in machine learning (ML) that specializes in natural language processing (NLP), enabling it to perform tasks like text generation, translation, summarization, and more. “
Leave a Reply
You must be logged in to post a comment.