The world of Artificial Intelligence is increasingly dominated by Large Language Models (LLMs) – sophisticated neural networks capable of understanding and generating human-like text with remarkable fluency. From powering chatbots and writing assistance tools to enabling complex data analysis, LLMs are transforming how we interact with technology. But where do these seemingly intelligent systems come from? The answer lies in a meticulous process called training.
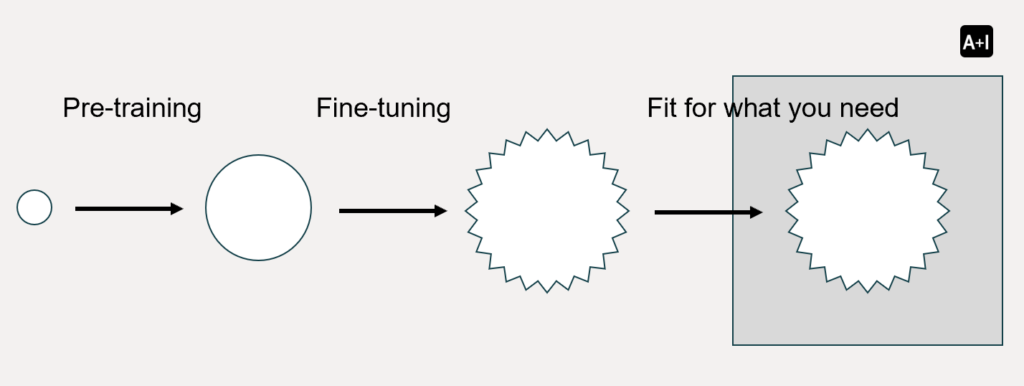
The image above provides a simplified visual representation of this journey: starting with a small seed (a basic model), undergoing a growth spurt (pre-training), then being carefully shaped (fine-tuning) until it perfectly fits a specific purpose. Let’s delve deeper into what LLM training entails, why it’s crucial, and the fundamental steps involved.
What is LLM Training
At its core, training an LLM is about teaching a massive neural network to understand the intricate patterns and relationships within vast amounts of text data. This isn’t about programming explicit rules. Instead, it’s about exposing the model to countless examples and allowing it to learn the underlying structure of language through statistical inference.
Think of it like teaching a child to speak and understand. You wouldn’t give them a rigid set of grammatical rules all at once. Instead, you’d immerse them in language – speaking to them, reading stories, and correcting their mistakes. Over time, the child internalizes the nuances of vocabulary, grammar, syntax and context. LLM training follows a similar principle, but on a much larger scale.
Why Do We Need to Train LLMs
The necessity of training LLMs stems from the inherent complexity and ambiguity of human language. Here’s why pre-existing, untrained models are insufficient:
- Lack of Foundational Knowledge: A freshly initialized LLM is like a blank slate. It has no understanding of words, their meanings, how they relate to each other, or the structure of sentences and paragraphs. Training provides this foundational knowledge.
- General-Purpose vs. Specific Needs: While a pre-trained LLM gains a broad understanding of language, it might not be optimized for specific tasks or domains. For instance, a general LLM might be able to write a short story, but it might not understand the technical jargon of medical research or the specific tone required for customer service interactions.
- Adapting to Specific Styles and Formats: Different applications require different writing styles and output formats. Training allows us to tailor an LLM to generate code, translate languages accurately, summarize news articles concisely, or even adopt a particular persona in a chatbot.
- Incorporating Domain-Specific Knowledge: Many real-world applications require LLMs to possess knowledge specific to a particular industry or field. Training on relevant datasets allows the model to learn and utilize this specialized information.
- Improving Performance and Accuracy: Fine-tuning, in particular, helps to refine the model’s responses, reduce errors, and improve its overall performance on targeted tasks.
In essence, training transforms a general-purpose language model into a specialized tool capable of delivering value in specific applications.
How to Train an LLM: The Two Key Stages
The image at the beginning of this article highlights two crucial stages in the training process: Pre-training and Fine-tuning.
1. Pre-training: Building the Foundation
This is the initial, large-scale training phase where the LLM is exposed to massive amounts of raw text data. This data can include everything from books and articles to websites and code repositories – essentially, a significant portion of the digital text available.
During pre-training, the model learns the fundamental building blocks of language. It develops an understanding of:
- Vocabulary: Recognizing individual words and their basic meanings.
- Syntax: Learning the grammatical rules and structures of sentences.
- Semantics: Grasping the relationships between words and their contextual meanings.
- World Knowledge: Implicitly absorbing factual information present in the training data.
The primary objective of pre-training is to create a general-purpose language model that possesses a broad understanding of language and can perform basic language-related tasks. This stage typically involves self-supervised learning techniques. One common method is Masked Language Modelling, where the model is given a sentence with some words hidden and tasked with predicting the missing words based on the surrounding context. This forces the model to learn the relationships between words and their meanings.
As shown in the image, pre-training takes a relatively small and untrained model (i.e. the small circle), and expands its understanding significantly (i.e. the large circle).
2. Fine-tuning: Tailoring for Specific Tasks
Once the LLM has undergone pre-training and possesses a general understanding of language, the fine-tuning stage comes into play. This involves training the pre-trained model on smaller, task-specific datasets. The goal here is to adapt the model’s general knowledge to perform specific downstream tasks with higher accuracy and efficiency.
Examples of fine-tuning tasks include:
- Text Classification: Categorizing text into predefined categories (e.g., spam detection, sentiment analysis).
- Question Answering: Providing accurate answers to questions based on a given context.
- Text Generation (Specific Styles): Generating creative content, writing summaries, or completing sentences in a desired style.
- Translation: Converting text from one language to another.
- Dialogue Generation: Engaging in coherent and contextually relevant conversations.
During fine-tuning, the model’s existing knowledge is leveraged and refined. The task-specific data provides the necessary examples for the model to learn the nuances and patterns relevant to that particular application. This often involves supervised learning, where the model is presented with input-output pairs (e.g., a question and its correct answer).
Takeaways
Training Large Language Models is a complex but essential process that transforms raw computational power into intelligent language understanding and generation capabilities. From the initial broad learning in pre-training to the precise adaptation in fine-tuning, each stage plays a crucial role in creating LLMs that can effectively address a wide range of real-world challenges. As AI continues to evolve, understanding the fundamentals of LLM training will become increasingly important for anyone seeking to leverage the power of these transformative technologies.
Leave a Reply
You must be logged in to post a comment.